Empirical Benchmark Evidence
Demonstrating that catastrophic forgetting behaviors are observable, reproducible, and reversible across multiple base models under consistent evaluation conditions.
Evaluation Methodology
All benchmarks were executed using the same evaluation harness, task definitions, and zero-shot configuration across all training phases. This consistency ensures that observed performance changes reflect genuine model state transitions rather than evaluation artifacts.
The evaluation framework assessed models across three distinct phases:
- Baseline: Initial model capabilities before domain-specific training
- Math Training: Post-training state after mathematics-focused fine-tuning
- ARC Recovery: Performance recovery following targeted adaptation
Key benchmarks evaluated include ARC Challenge (reasoning), GSM8K with Chain-of-Thought (mathematical reasoning), HellaSwag (common sense), and Winogrande (logical inference). These benchmarks were selected to capture both domain-specific and general capabilities.
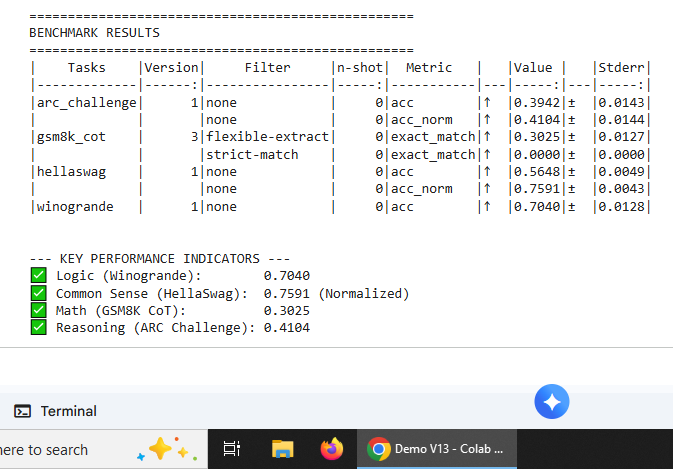
Nous-Hermes-llama-2-7b
First validation model demonstrating selective degradation and recovery patterns
Initial model state prior to domain-specific training. Establishes baseline performance across all evaluated benchmarks.
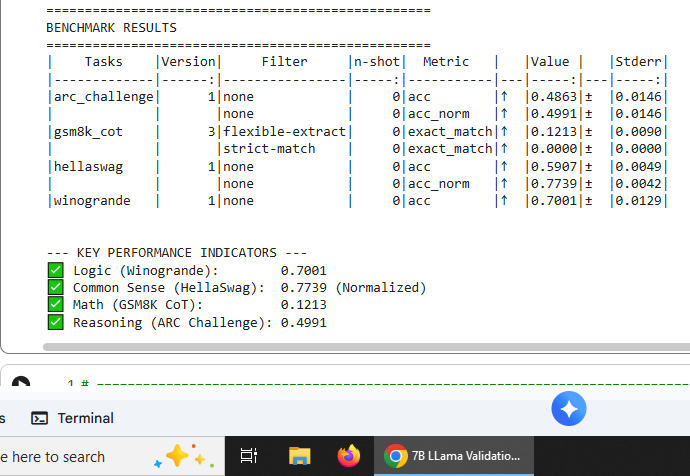
Post mathematics-focused fine-tuning. Demonstrates selective degradation in ARC Challenge while maintaining or improving performance in other domains.
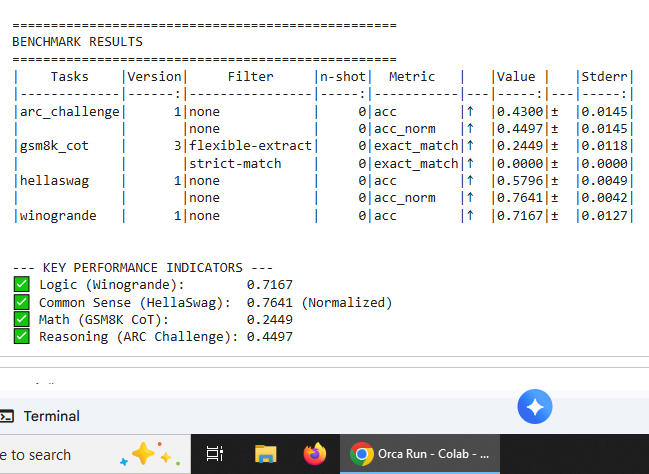
Recovery phase demonstrating restoration of ARC performance without reintroduction of original training data, supporting inference misrouting hypothesis.
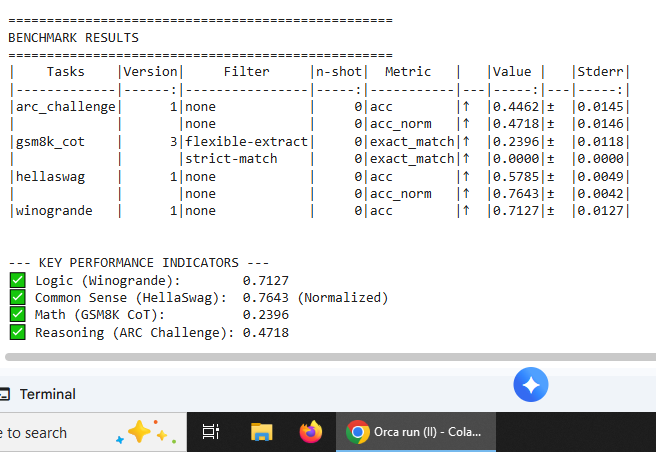
Llama-2-7b-chat-hf
Independent validation across a second model family confirming reproducibility of observed patterns
Baseline evaluation establishing initial capability profile. Provides comparison point for subsequent training phases.
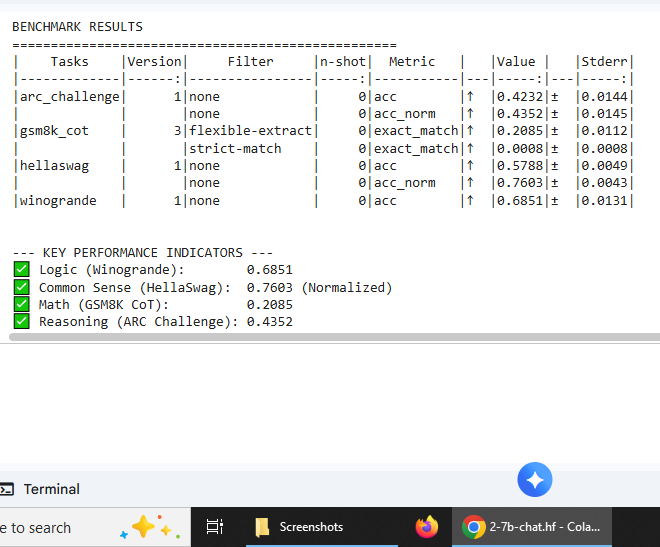
Mathematics-focused training phase exhibiting consistent degradation patterns with Nous-Hermes model, confirming cross-model reproducibility.
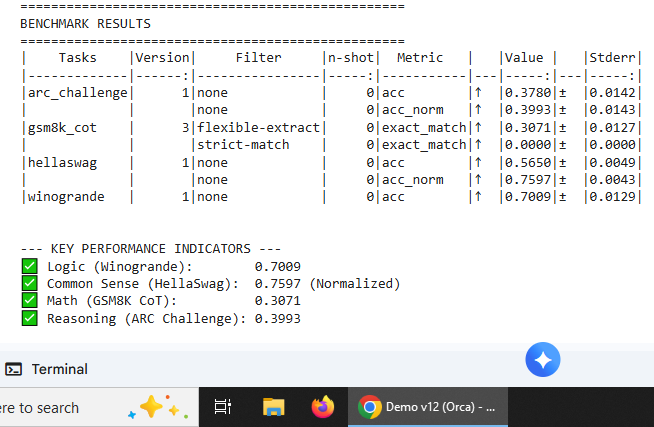
Recovery phase validating that observed degradation is reversible across different model architectures and training histories.